
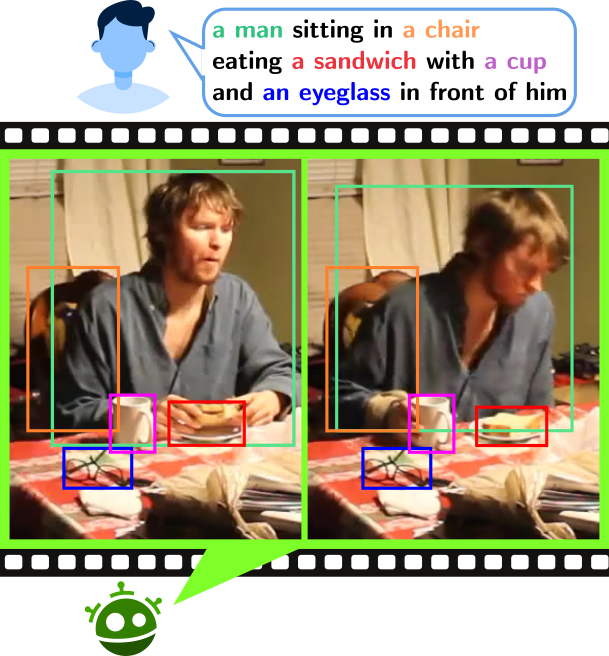
Type-to-Track: Retrieve Any Object via Prompt-based Tracking
One of the recent trends in vision problems is to use
natural language captions to describe the objects of interest. This approach
can overcome some limitations of traditional methods that rely on bounding
boxes or category annotations. This paper introduces a novel paradigm for
Multiple Object Tracking called Type-to-Track, which allows users to
track objects in videos by typing natural language descriptions. We present
a new dataset for that Grounded Multiple Object Tracking task, called
GroOT, that contains videos with various types of objects and their
corresponding textual captions describing their appearance and action in
detail. Additionally, we introduce two new evaluation protocols and
formulate evaluation metrics specifically for this task. We develop a new
efficient method that models a transformer-based eMbed-ENcoDE-extRact
framework (MENDER) using the third-order tensor decomposition. The
experiments in five scenarios show that our MENDER approach
outperforms another two-stage design in terms of accuracy and efficiency, up
to 14.7% accuracy and 4× speed faster.
Project Page | Paper | Poster | Video
Project Page | Paper | Poster | Video
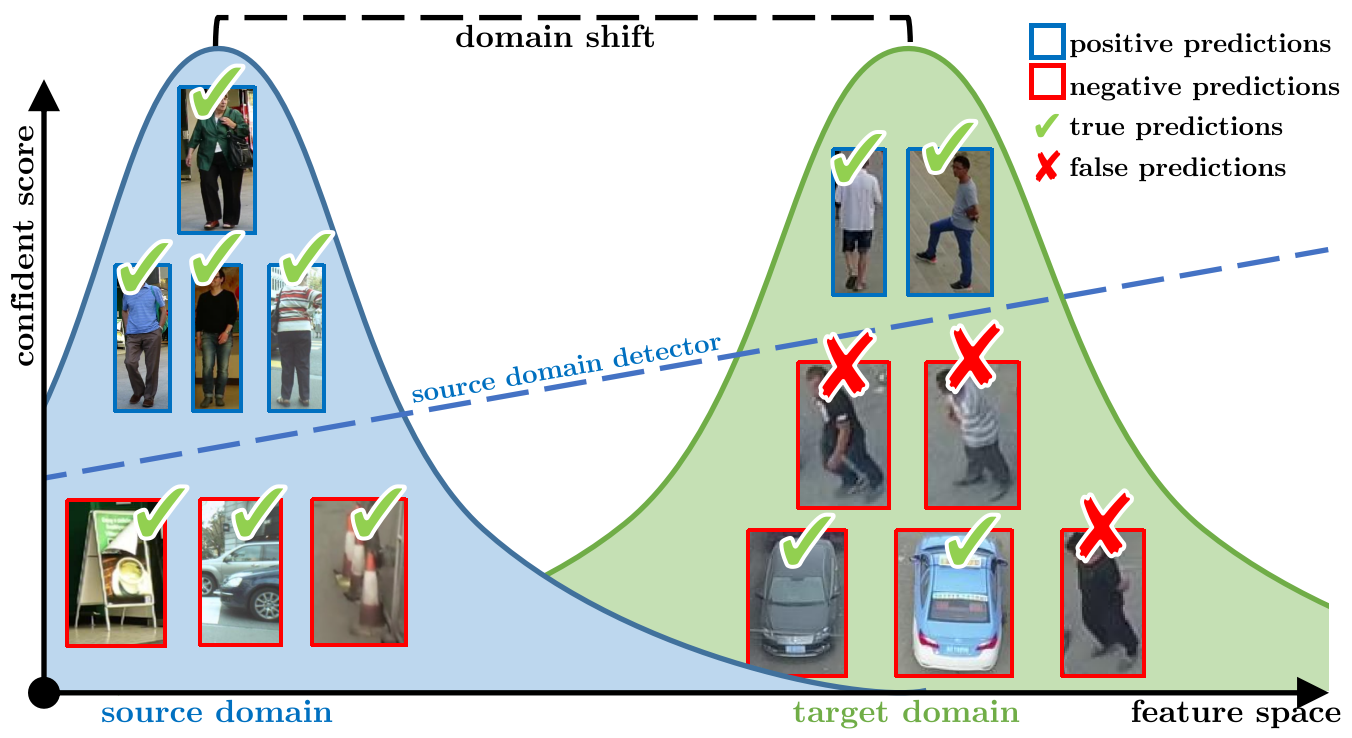
UTOPIA: Unconstrained Tracking Objects without Preliminary Examination via Cross-Domain Adaptation
Multiple Object Tracking (MOT) aims to find bounding boxes
and identities of targeted objects in consecutive video frames. While
fully-supervised MOT methods have achieved high accuracy on existing
datasets, they cannot generalize well on a newly obtained dataset or a new
unseen domain. In this work, we first address the MOT problem from the
cross-domain point of view, imitating the process of new data acquisition in
practice. Then, a new cross-domain MOT adaptation from existing datasets is
proposed without any pre-defined human knowledge in understanding and
modeling objects. It can also learn and update itself from the target data
feedback. The intensive experiments are designed on four challenging
settings, including MOTSynth to MOT17, MOT17 to MOT20, MOT17 to VisDrone,
and MOT17 to DanceTrack. We then prove the adaptability of the proposed
self-supervised learning strategy. The experiments also show superior
performance on tracking metrics MOTA and IDF1, compared to fully supervised,
unsupervised, and self-supervised state-of-the-art methods.
Paper
Paper

SoGAR: Self-supervised Spatiotemporal Attention-based Social Group Activity Recognition
This paper introduces a novel approach to Social Group
Activity Recognition (SoGAR) using Self-supervised Transformers network that
can effectively utilize unlabeled video data. To extract spatio-temporal
information, we created local and global views with varying frame rates. Our
self-supervised objective ensures that features extracted from contrasting
views of the same video were consistent across spatio-temporal domains. Our
proposed approach is efficient in using transformer-based encoders to
alleviate the weakly supervised setting of group activity recognition. By
leveraging the benefits of transformer models, our approach can model
long-term relationships along spatio-temporal dimensions. Our proposed SoGAR
method achieved state-of-the-art results on three group activity recognition
benchmarks, namely JRDB-PAR, NBA, and Volleyball datasets, surpassing the
current numbers in terms of F1-score, MCA, and MPCA metrics.
Paper
Paper

SPARTAN: Self-supervised Spatiotemporal Transformers Approach to Group Activity Recognition
In this paper, we propose a new, simple, and effective
Self-supervised Spatio-temporal Transformers (SPARTAN) approach to Group
Activity Recognition (GAR) using unlabeled video data. Given a video, we
create local and global Spatio-temporal views with varying spatial patch
sizes and frame rates. The proposed self-supervised objective aims to match
the features of these contrasting views representing the same video to be
consistent with the variations in spatiotemporal domains. To the best of our
knowledge, the proposed mechanism is one of the first works to alleviate the
weakly supervised setting of GAR using the encoders in video transformers.
Furthermore, using the advantage of transformer models, our proposed
approach supports long-term relationship modeling along spatio-temporal
dimensions. The proposed SPARTAN approach performs well on two group
activity recognition benchmarks, including NBA and Volleyball datasets, by
surpassing the state-of-the-art results by a significant margin in terms of
MCA and MPCA metrics.
Paper
Paper
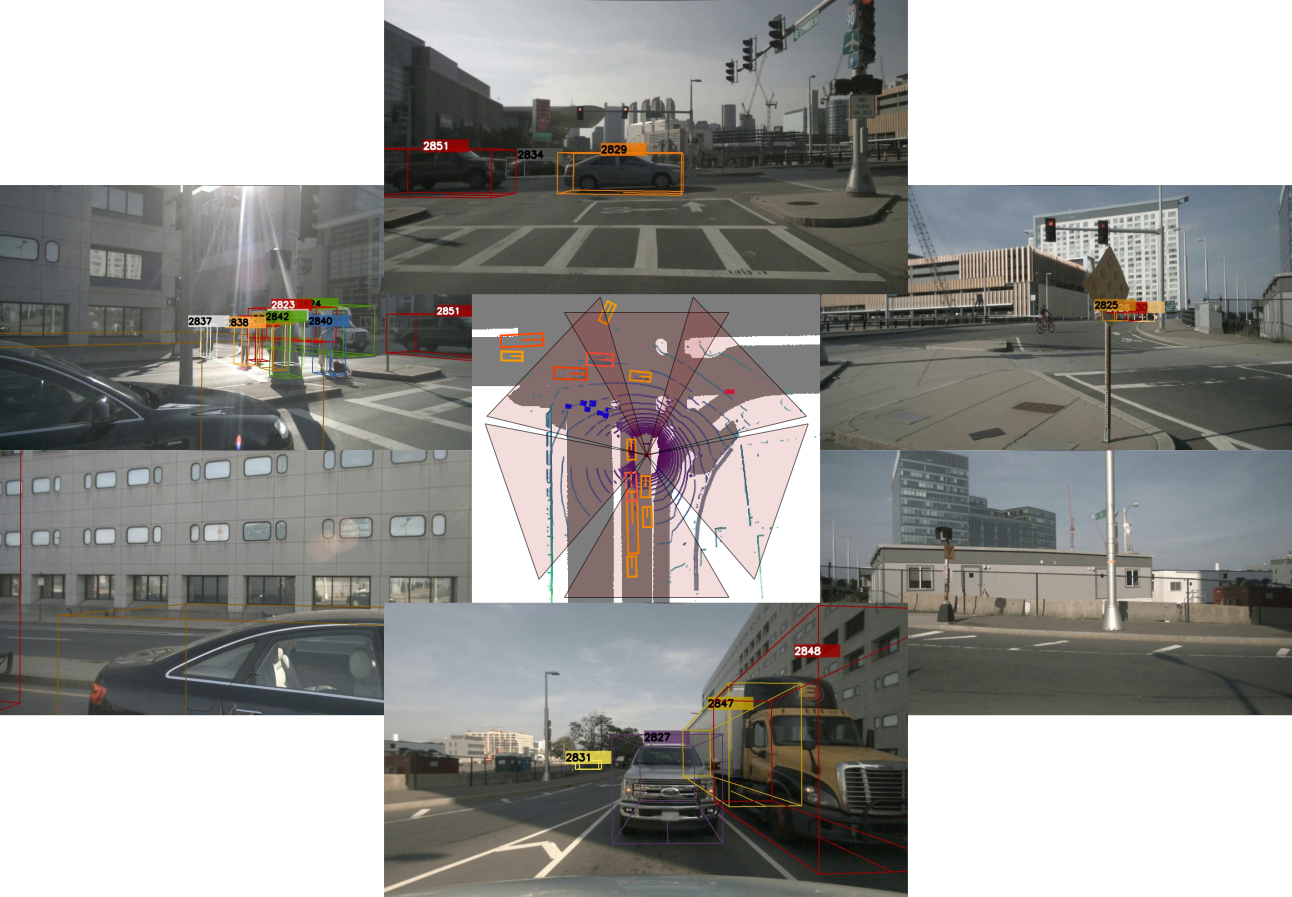
Multi-Camera Multi-Object Tracking on the Move via Single-Stage Global Association Approach
The development of autonomous vehicles generates a
tremendous demand for a low-cost solution with a complete set of camera
sensors capturing the environment around the car. It is essential for object
detection and tracking to address these new challenges in multi-camera
settings. In order to address these challenges, this work introduces novel
Single-Stage Global Association Tracking approaches to associate one or more
detection from multi-cameras with tracked objects. These approaches aim to
solve fragment-tracking issues caused by inconsistent 3D object detection.
Moreover, our models also improve the detection accuracy of the standard
vision-based 3D object detectors in the nuScenes detection challenge. The
experimental results on the nuScenes dataset demonstrate the benefits of the
proposed method by outperforming prior vision-based tracking methods in
multi-camera settings.
Paper
Paper
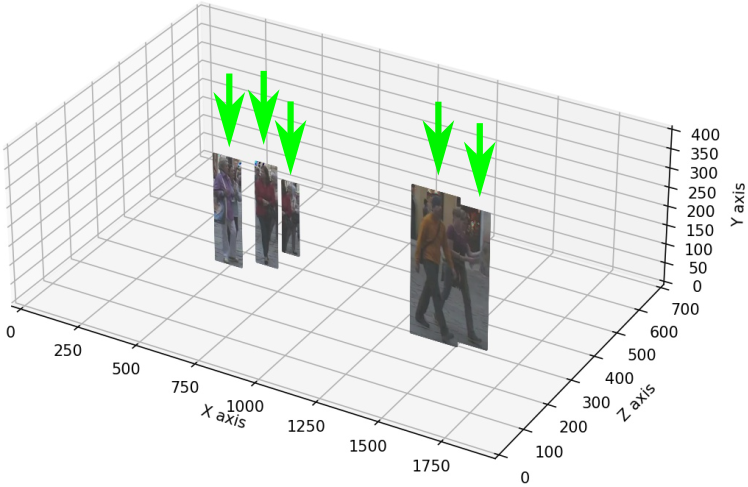
Depth Perspective-aware Multiple Object Tracking
This paper aims to tackle Multiple Object Tracking (MOT),
an important problem in computer vision but remains challenging due to many
practical issues, especially occlusions. Indeed, we propose a new real-time
Depth Perspective-aware Multiple Object Tracking (DP-MOT) approach to tackle
the occlusion problem in MOT. A simple yet efficient Subject-Ordered Depth
Estimation (SODE) is first proposed to automatically order the depth
positions of detected subjects in a 2D scene in an unsupervised manner.
Using the output from SODE, a new Active pseudo-3D Kalman filter, a simple
but effective extension of Kalman filter with dynamic control variables, is
then proposed to dynamically update the movement of objects. In addition, a
new high-order association approach is presented in the data association
step to incorporate first-order and second-order relationships between the
detected objects. The proposed approach consistently achieves
state-of-the-art performance compared to recent MOT methods on standard MOT
benchmarks.
Paper
Paper
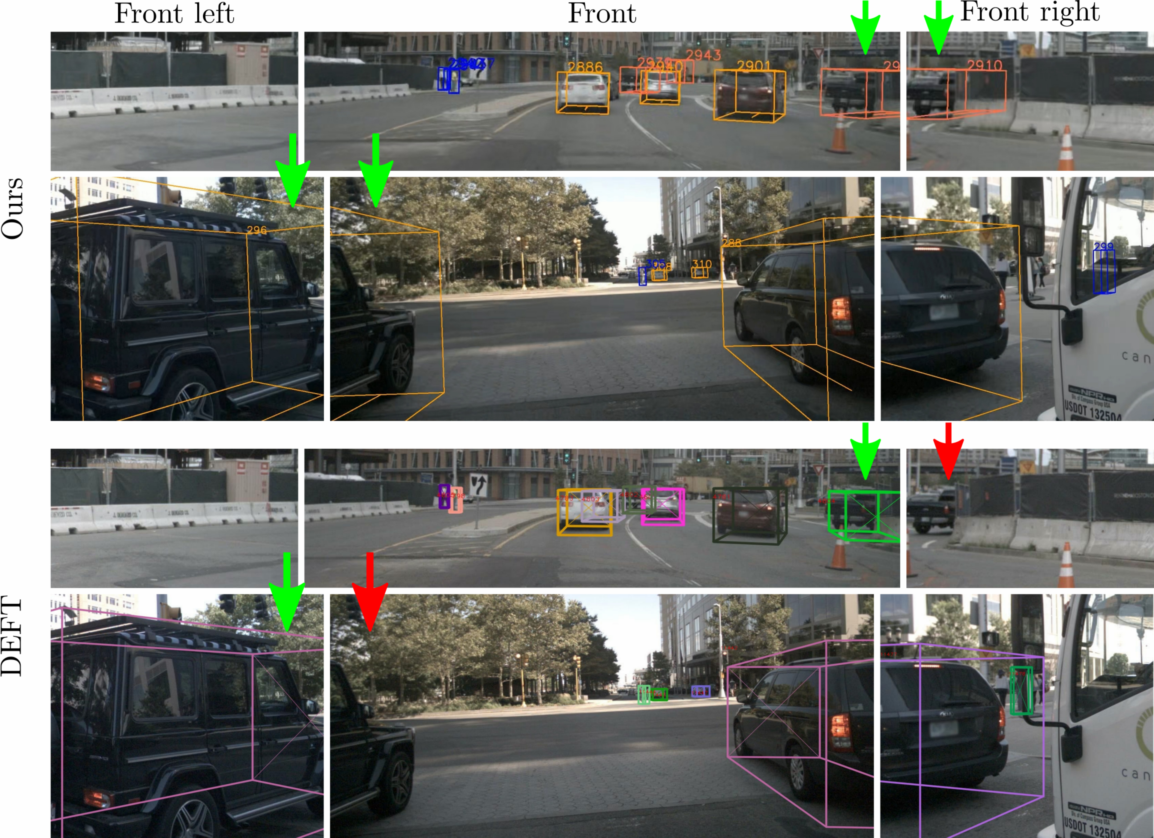
Multi-Camera Multiple 3D Object Tracking on the Move for Autonomous Vehicles
The development of autonomous vehicles provides an
opportunity to have a complete set of camera sensors capturing the
environment around the car. Thus, it is important for object detection and
tracking to address new challenges, such as achieving consistent results
across views of cameras. To address these challenges, this work presents a
new Global Association Graph Model with Link Prediction approach to predict
existing tracklets location and link detections with tracklets via
cross-attention motion modeling and appearance re-identification. This
approach aims at solving issues caused by inconsistent 3D object detection.
Moreover, our model exploits to improve the detection accuracy of a standard
3D object detector in the nuScenes detection challenge. The experimental
results on the nuScenes dataset demonstrate the benefits of the proposed
method to produce SOTA performance on the existing vision-based tracking
dataset.
Paper | Poster | Video
Paper | Poster | Video
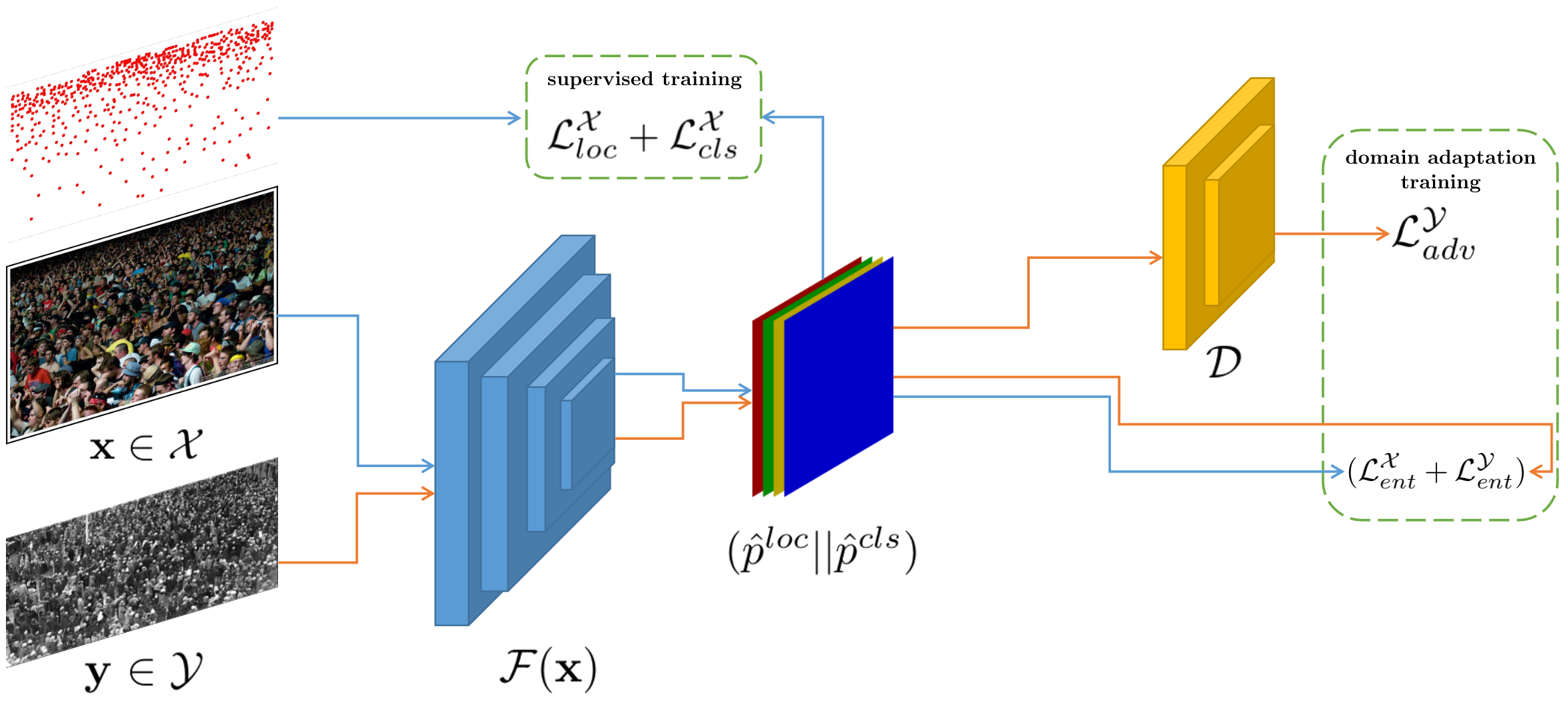
Self-supervised Domain Adaptation in Crowd Counting
Self-training crowd counting has not been attentively
explored though it is one of the important challenges in computer vision. In
practice, the fully supervised methods usually require an intensive resource
of manual annotation. In order to address this challenge, this work
introduces a new approach to utilize existing datasets with ground truth to
produce more robust predictions on unlabeled datasets, named domain
adaptation, in crowd counting. While the network is trained with labeled
data, samples without labels from the target domain are also added to the
training process. In this process, the entropy map is computed and minimized
in addition to the adversarial training process designed in
parallel.
Experiments on Shanghaitech, UCF_CC_50, and UCF-QNRF datasets prove a more generalized improvement of our method over the other state-of-the-arts in the cross-domain setting.
Project Page | Paper
Experiments on Shanghaitech, UCF_CC_50, and UCF-QNRF datasets prove a more generalized improvement of our method over the other state-of-the-arts in the cross-domain setting.
Project Page | Paper

DyGLIP: A Dynamic Graph Model with Link Prediction for Accurate Multi-Camera Multiple Object Tracking
Multi-Camera Multiple Object Tracking (MC-MOT) is a
significant computer vision problem due to its emerging applicability in
several real-world applications. Despite a large number of existing works,
solving the data association problem in any MC-MOT pipeline is arguably one
of the most challenging tasks. Developing a robust MC-MOT system, however,
is still highly challenging due to many practical issues such as
inconsistent lighting conditions, varying object movement patterns, or the
trajectory occlusions of the objects between the cameras. To address these
problems, this work, therefore, proposes a new Dynamic Graph Model with Link
Prediction (DyGLIP) approach to solve the data association task. Compared to
existing methods, our new model offers several advantages, including better
feature representations and the ability to recover from lost tracks during
camera transitions. Moreover, our model works gracefully regardless of the
overlapping ratios between the cameras. Experimental results show that we
outperform existing MC-MOT algorithms by a large margin on several practical
datasets.
Notably, our model works favorably on online settings but can be extended to an incremental approach for large-scale datasets.
Paper | Poster | Video | Code
Notably, our model works favorably on online settings but can be extended to an incremental approach for large-scale datasets.
Paper | Poster | Video | Code